
The landscape of Large Language Models (LLMs) has evolved at a breakneck pace. By 2025, the industry has moved far beyond simple chatbots and text generators into an era of dependable AI infrastructure—where models are evaluated not only by their parameter count, but by their internal architecture, training lifecycle, efficiency, and agentic capabilities.
Whether you are a developer building autonomous agents, an ML engineer selecting the right model, or an enthusiast tracking the AI arms race, understanding these distinctions is now essential.
This article provides a technical overview of modern LLM architectures, their training stages, and the rise of agentic AI systems that define the state of the art (SOTA) in 2025.
What You'll Learn
This deep-dive covers Transformer variants (decoder-only, encoder-decoder, MoE), the foundational vs. instruct model lifecycle, and why decoder-only architectures dominate agentic AI systems in 2025.
1. The Architectural Blueprint: How Models "Think"
At the core of every modern LLM lies the Transformer architecture, first introduced in the seminal 2017 paper Attention Is All You Need by Vaswani et al. While nearly all leading models still rely on Transformers, how they arrange and activate these components varies dramatically depending on their intended use case.

Figure 1: Transformer architecture with encoder-decoder stacks – The Illustrated Transformer
Decoder-Only Models: The Generation King
Decoder-only architectures dominate today's LLM ecosystem. These models are trained to predict the next token using unidirectional self-attention, making them exceptionally good at generation.
Why Decoder-Only is SOTA
Decoder-only models excel at free-form generation, reasoning, and conversation. They scale efficiently with larger context windows and are naturally suited for agentic behavior—powering most conversational AI systems today.
Major Players
| Organization | Models | Documentation |
|---|---|---|
| OpenAI | GPT-4.x, GPT-5.x, o-series | OpenAI Research |
| Anthropic | Claude 3.5, Claude 4 | Anthropic AI |
| Meta | Llama 3, Llama 4 | Meta AI Research |
Key Research Papers:
- Language Models are Few-Shot Learners — GPT-3 paper (Brown et al., 2020)
- Llama 2: Open Foundation and Fine-Tuned Chat Models — Touvron et al., 2023
Encoder-Decoder Models: The Translation Specialist
Encoder-decoder models split understanding and generation into two distinct phases:
- The encoder processes and understands the input using bidirectional attention
- The decoder generates output via cross-attention to encoder states

Figure 2: Encoder-Decoder architecture showing encoding and decoding components – The Illustrated Transformer
Why Encoder-Decoder Excels
- High precision for translation, summarization, and structured transformations
- Strong alignment between input and output sequences
- Lower hallucination rates for constrained tasks
- Efficient for sequence-to-sequence operations
When to Use Encoder-Decoder
Choose encoder-decoder architectures when you need precise input-to-output transformations: machine translation, document summarization, or structured data generation where output must closely mirror input semantics.
Major Players
| Organization | Models | Documentation |
|---|---|---|
| Google DeepMind | T5, PaLM-based variants | Google Research |
| Meta FAIR | BART, mBART | FAIR Research |
Key Research Papers:
- Exploring the Limits of Transfer Learning with T5 — Raffel et al., 2019
- BART: Denoising Sequence-to-Sequence Pre-training — Lewis et al., 2019
Mixture of Experts (MoE): The Efficiency Giant
MoE models introduce sparse activation. Instead of activating every parameter for every request, a router selects a small subset of specialized "experts" to handle each query.
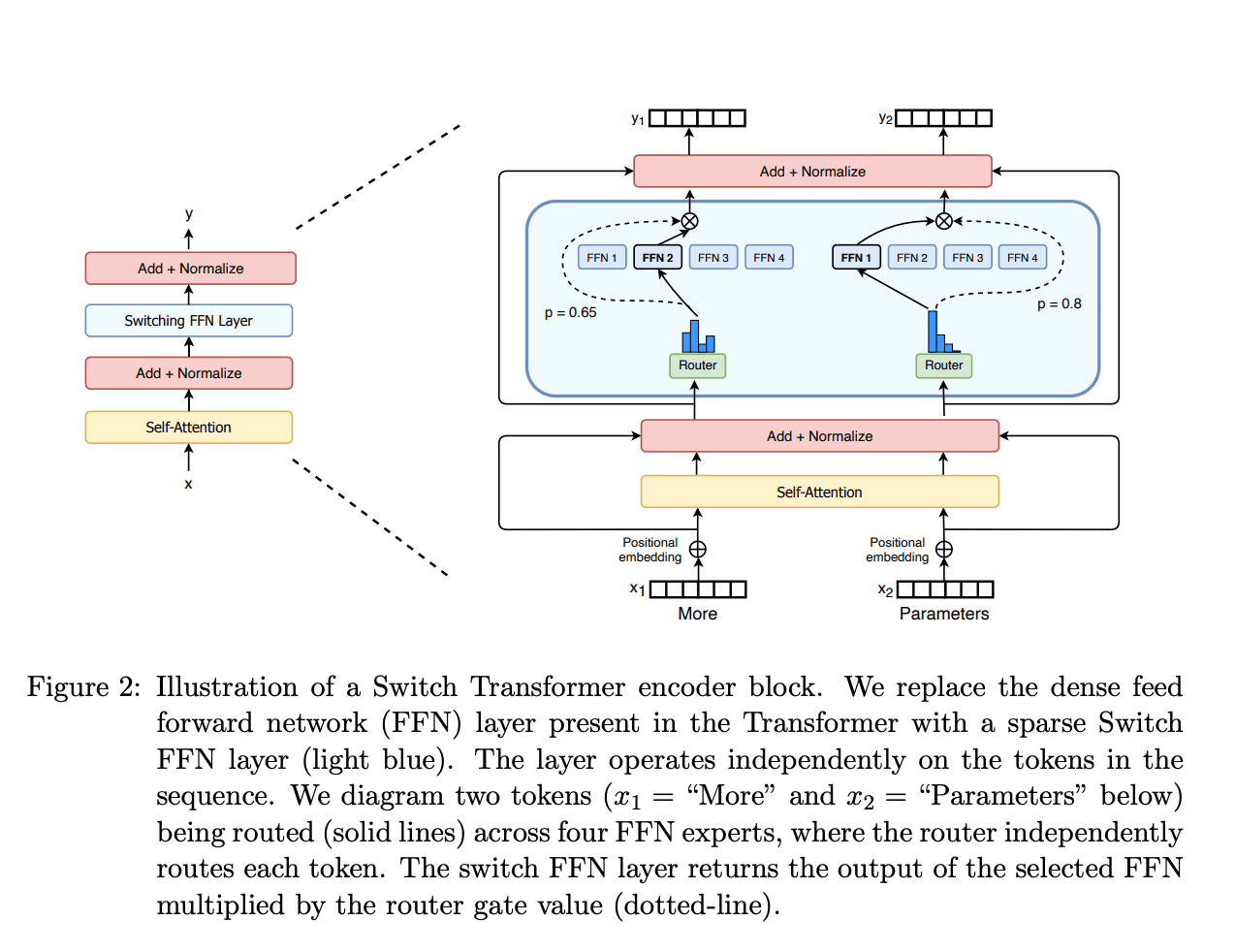
Figure 3: Sparse MoE routing mechanism – Switch Transformers
MoE Efficiency Gains
MoE architectures can scale to trillions of parameters while only activating a fraction per inference. DeepSeek-V3 activates ~37B of its 671B parameters per token, achieving frontier performance at a fraction of the compute cost.
Why MoE is SOTA for Scale
- Scales to trillions of parameters while maintaining efficiency
- Lower inference cost per token (sparse activation)
- High throughput for enterprise workloads
- Better specialization across domains via expert routing
Major Players
| Organization | Models | Active/Total Params | Documentation |
|---|---|---|---|
| DeepSeek | DeepSeek-V3 | 37B/671B | DeepSeek AI |
| Mistral AI | Mixtral 8x7B, 8x22B | 12B/46B, 39B/141B | Mistral AI |
| Gemini 1.5 variants | Undisclosed | Google DeepMind |
Key Research Papers:
- Mixtral of Experts — Jiang et al., 2024
- Switch Transformers: Scaling to Trillion Parameter Models — Fedus et al., 2021
- DeepSeek-V3 Technical Report — DeepSeek AI, 2024
2. Foundational vs. Instruct Models: The Lifecycle of an LLM
A common misconception is that "Foundational" and "Instruct" models refer to different architectures. In reality, they represent different stages of training.
Foundational (Base) Models
These are the raw models, trained on massive corpora using self-supervised learning to predict the next token.
Base Model Limitations
Foundational models have broad world knowledge but are not inherently helpful or safe. They're prone to hallucinations, may not follow instructions reliably, and require careful prompting for useful outputs.
Characteristics
- Broad world knowledge from diverse training data
- Not inherently helpful or safe
- Prone to hallucinations and non-compliance
- Require careful prompting for useful outputs
Examples: GPT-4-base, Llama-3-70B-base, Mistral-7B-v0.1
Instruct (Aligned) Models
Instruct models are Foundational models that have gone through alignment training, typically involving:
Training Pipeline for Instruct Models
──────────────────────────────────────────────────────────────
1. Pre-training (Base Model)
└─→ Self-supervised next-token prediction
└─→ Trillions of tokens from web, books, code
2. Supervised Fine-Tuning (SFT)
└─→ High-quality instruction-response pairs
└─→ Human-written demonstrations
3. Preference Optimization
└─→ RLHF: Reinforcement Learning from Human Feedback
└─→ DPO: Direct Preference Optimization
└─→ Constitutional AI: Self-improvement via principles
4. Safety & Red-teaming
└─→ Adversarial testing
└─→ Guardrails and refusal trainingWhy Instruct Models Matter
Instruct models follow user instructions reliably, exhibit safer and more predictable behavior, produce fewer harmful outputs, and are required for production deployment.
Examples: GPT-4-turbo, Claude-3.5-Sonnet, Llama-3-70B-Instruct
Key Research Papers:
- InstructGPT: Training language models to follow instructions — Ouyang et al., 2022
- Constitutional AI: Harmlessness from AI Feedback — Anthropic, 2022
- Direct Preference Optimization — Rafailov et al., 2023
3. The Rise of Agentic Models (SOTA 2025)
The most significant shift in 2025 is the dominance of Agentic AI systems.
Unlike traditional LLMs that simply generate text, agents can reason, plan, and act—often across multiple steps and tools.
Why Decoder-Only Models Power Agents
Most agentic systems are built on decoder-only architectures because they excel at:
| Capability | Description | Example |
|---|---|---|
| Reasoning traces | Breaking problems into intermediate steps | OpenAI o1/o3, DeepSeek-R1 |
| Tool usage | Structured function calling for APIs, databases | Claude tool use, GPT function calling |
| Context management | Efficient long-context via KV caching | 128K–1M+ token windows |
| Multi-step planning | Coherent task execution across interactions | ReAct, Plan-and-Execute patterns |
The ReAct Pattern
ReAct (Reasoning + Acting) combines chain-of-thought reasoning with tool use. The model alternates between thinking ("I need to search for X") and acting (calling a search API), creating a powerful agentic loop. See the ReAct paper.
Key Research Papers:
- ReAct: Synergizing Reasoning and Acting in Language Models — Yao et al., 2022
- Toolformer: Language Models Can Teach Themselves to Use Tools — Schick et al., 2023
- Chain-of-Thought Prompting Elicits Reasoning in LLMs — Wei et al., 2022
Current SOTA Models by Category (Late 2025)
| Category | Leading Models | Key Strength |
|---|---|---|
| Reasoning & Math | DeepSeek-R1, OpenAI o-series | Multi-step problem solving with verification |
| General Purpose | GPT-5.x, Claude 4 Opus | Balanced performance across diverse tasks |
| Open Source | Llama 4, DeepSeek-V3 | Community accessibility, fine-tuning freedom |
| Enterprise | Gemini 3 Pro, Amazon Nova | Tool integration, compliance, scale |
| Code Generation | Claude Code, GitHub Copilot | Programming assistance, codebase understanding |
4. Key Players Defining the 2025 AI Landscape
The Frontier Labs
OpenAI
- Advanced reasoning models (o-series with extended thinking)
- GPT-5.x family for general intelligence
- Leading in agentic planning capabilities
- OpenAI Platform Documentation
Anthropic
- Safety-first scaling approach (Constitutional AI)
- Claude 4 family with 200K+ context windows
- Strong tool use and structured outputs
- Anthropic Research Papers
Open-Source Champions
Meta AI
- Open-weights models at frontier scale
- Llama ecosystem driving academic research
- Community-driven improvements and fine-tunes
- Meta AI Research
DeepSeek
- Efficient MoE-based architectures
- Competitive with closed-source models at lower cost
- Focus on reasoning capabilities (DeepSeek-R1)
- DeepSeek Technical Reports
Ecosystem Giants
Google DeepMind
- Deep integration across Google products
- Gemini family with native multimodal capabilities
- Scientific breakthroughs (AlphaFold 3, AlphaGeometry)
- Google DeepMind Research
Amazon Web Services
- LLM infrastructure via Amazon Bedrock
- Massive context windows (up to 300K tokens)
- Multi-model orchestration platform
- AWS AI Services
Microsoft
- Azure OpenAI Service for enterprise
- Phi small language models for edge deployment
- GitHub Copilot for developer productivity
- Microsoft Research AI
5. Practical Implications for Developers
Choosing the Right Architecture
Task Type → Recommended Architecture
───────────────────────────────────────────────────────────────
Chat & Conversational Agents → Decoder-only (GPT, Claude, Llama)
Translation & Summarization → Encoder-decoder (T5, BART, mT5)
High-throughput Applications → MoE (Mixtral, DeepSeek-V3)
Resource-constrained / Edge → Small models (Phi-3, Gemma 2)
Code Generation → Code-specialized (Claude, Codex)Key Decision Factors
Model Selection Checklist
Consider these factors when choosing an LLM for your application:
| Factor | Considerations |
|---|---|
| Latency | Real-time apps need smaller models or edge deployment |
| Cost | MoE models offer better cost-per-token at scale |
| Safety | Production apps require instruct models with RLHF |
| Integration | API services vs. self-hosted infrastructure |
| Context Length | Task-dependent: 4K for chat, 128K+ for RAG/documents |
| Privacy | Self-hosted open-source for sensitive data |
Conclusion
In 2025, the defining question is no longer:
"Which model is the biggest?"
But rather:
"Which architecture fits the task?"
Decision Framework
- Agents and reasoning → Decoder-only architectures (GPT, Claude, Llama)
- Efficiency at scale → Mixture of Experts (DeepSeek-V3, Mixtral)
- Precision transformations → Encoder-decoder models (T5, BART)
- Domain expertise → Fine-tuned instruct models
LLMs are no longer products—they are infrastructure, and understanding their internal design is now a core engineering skill.
The future belongs to developers who understand not just how to use these models, but why each architecture exists and when to deploy it.
References & Further Reading
Primary Research Papers
- Vaswani, A., et al. (2017). Attention Is All You Need
- Brown, T., et al. (2020). Language Models are Few-Shot Learners
- Ouyang, L., et al. (2022). Training language models to follow instructions with human feedback
- Touvron, H., et al. (2023). Llama 2: Open Foundation and Fine-Tuned Chat Models
- Jiang, A. Q., et al. (2024). Mixtral of Experts
- DeepSeek AI. (2024). DeepSeek-V3 Technical Report
Educational Resources
- The Illustrated Transformer — Jay Alammar
- Hugging Face NLP Course — Free comprehensive course
- LLM Visualization — Interactive 3D model visualization
- Papers With Code — ML papers with implementations
Technical Documentation
- Hugging Face Transformers — Model library
- LangChain Documentation — Agent frameworks
- OpenAI API Docs — GPT integration
- Anthropic Claude API — Claude integration
This article provides a technical overview for developers, ML engineers, and AI practitioners navigating the rapidly evolving LLM landscape. For the latest updates, follow the research publications from the organizations mentioned above.